选择合适硬件,释放深度学习强劲算力!
深度学习(Deep Learning)属于机器学习的子类,是目前热门的机器学习方法,但它并不意味着是机器学习的终点。主流研究领域中,最适合深度学习,发挥最高效率的是GPU服务器/工作站 。
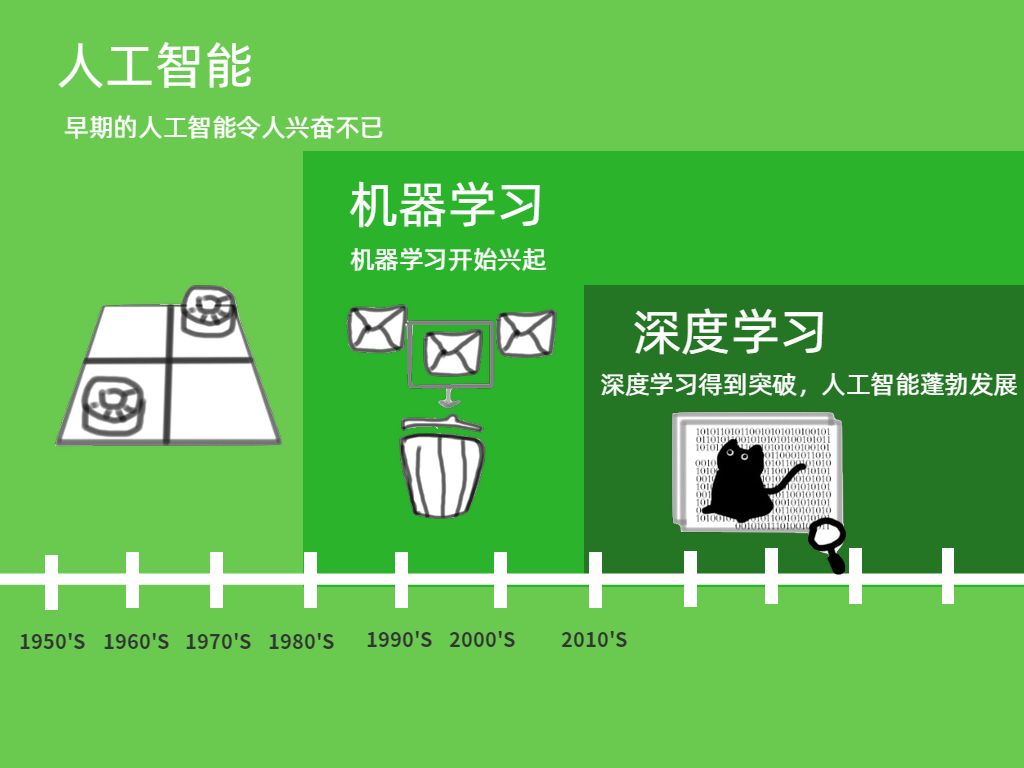
随着AI的广泛应用,深度学习已成为当前AI研究和运用的主流方式。面对海量数据的并行运算,AI对于算力的要求不断提升,对硬件的运算速度及功耗提出了新的挑战。
目前,除通用CPU外,作为硬件加速的GPU、NPU、FPGA等一些芯片处理器在深度学习的不同场景中发挥着各自的优势,但孰优孰劣?

首先,我们先来了解一下CPU
CPU
CPU中央处理器,是一块超大规模的集成电路,主要逻辑架构包括控制单元Control、运算单元ALU和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。

简单来说,就是计算单元、控制单元和存储单元。
CPU遵循的是冯诺依曼架构,其核心是存储程序、顺序执行。
CPU的架构中需要大量的空间去放置存储单元(Cache)和控制单元(Control)。
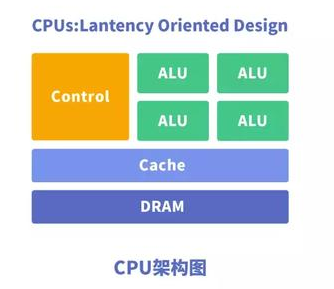
相比之下计算单元(ALU)只占据了一部分,所以它在大规模并行计算能力上极受限制,更擅长于逻辑控制。

CPU无法做到大量矩阵数据并行计算的能力
但GPU可以
GPU
GPU,即图形处理器,是一种由大量运算单元组成的大规模并行计算架构,专为同时处理多重任务而设计。

为什么GPU可以做到并行计算的能力?
GPU中也包含基本的计算单元、控制单元和存储单元,但GPU的架构与CPU有所不同。
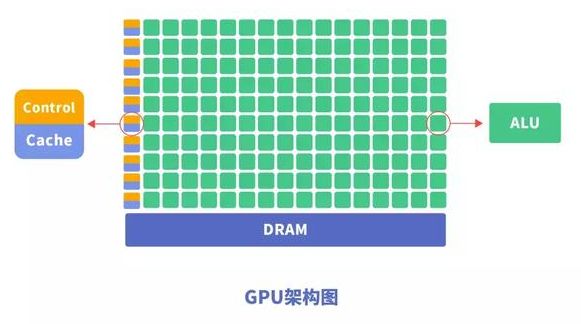
与CPU相比,CPU芯片空间的不到20%是ALU(计算单元),而GPU芯片空间的80%以上是ALU。即GPU拥有更多的ALU用于数据并行处理。
以Darknet构建的神经网络模型AlexNet、VGG-16及Restnet152在GPU Titan X, CPU Intel i7-4790K进行ImageNet分类任务预测的结果:
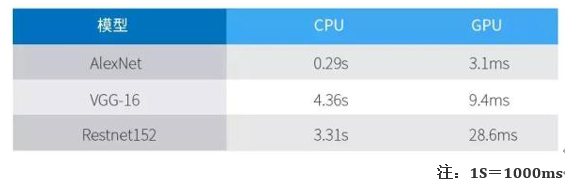
GPU处理神经网络数据远远高效于CPU
总结GPU具有如下特点:
多线程,提供了多核并行计算的基础结构,且核心数非常多,可以支撑大量数据的并行计算。
拥有更高的访问速度。
更高的浮点运算能力。
因此,GPU比CPU更适合深度学习中的大量数据训练、大量矩阵、卷积运算。
GPU虽然在并行计算能力上尽显优势,但并不能单独工作,需要CPU的协同处理,对于神经网络模型的构建和数据流的传递还是在CPU上进行。
缺点:存在功耗高,体积大的问题。
性能越高的GPU功耗越高,价格更昂贵,对于一些小型设备、移动设备来说将无法使用。
因此,一种体积小、功耗低、
计算效率高的专用芯片NPU诞生了
NPU
NPU—神经网络处理单元。
NPU工作原理是在电路层模拟人类神经元和突触,并且用深度学习指令集直接处理大规模的神经元和突触,一条指令完成一组神经元的处理。
特别擅长处理视频、图像类的海量多媒体数据,是专门为物联网人工智能而设计,用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题。

例如无人机对摄像头的重量和功耗有很高的要求,否则会影响起飞和续航能力, NPU的诞生让诸多监控摄像头等小型设备有了人工智能化的可能,迈出了人工智能从神秘的机房,跨向生活应用的一步。
除NPU外,在功耗及计算能力上
有一拼的还有FPGA。
FPGA
FPGA称为现场可编程逻辑门阵列。
用户可以根据自身的需求进行编程,能够有效的解决原有的器件门电路(用以实现基本逻辑运算和复合逻辑运算的单元电路)数较少的问题。与 CPU、GPU 相比,具有硬件二次开发的特点。

通俗点来说,FPGA的优势在于可以根据特定的应用去编程硬件(例如:如果应用里面的加法运算非常多就可以把大量的逻辑资源去实现加法器),但是GPU一旦设计完那就没法改动了,没法根据应用去调整硬件资源。
缺点:设计资源和布线资源的灵活度与通用处理器相比有很大的差距。
最后,我们来总结一下
1
CPU
CPU擅长各种设备的协调,协同其他处理器完成着不同的任务。
当然,目前最新一代第二代英特尔® 至强® 可扩展处理器中内置了英特尔® 深度学习加速技术,故我们也可使用CPU+算法来完成深度学习的任务。
2
GPU
GPU长于计算,适合深度学习中后台服务器大量数据训练、矩阵卷积运算。
GPU与NPU和FPGA相比,就像是我们现实中的公交车和出租车,GPU的适用领域广,而NPU与FPGA分别擅长不同领域。
所以在目前深度学习的领域中,主流用法仍然是GPU+算法。
3
NPU、FPGA
NPU、FPGA在性能、面积、功耗等方面有较大优势,能更好的加速神经网络计算。
但FPGA的特点在于开发使用硬件描述语言,开发门槛相对GPU、NPU高。
Attention:在使用CPU/NPU/FPGA+算法的时候,需要根据硬件平台做出相应算法的修改,否则无法发挥出硬件的最佳性能。
综上,每种处理器都有它的优势和不足。关键需要在不同的应用场景中,根据需求权衡利弊,选择最合适的加速设备,将硬件性能发挥到极致,获得更大算力。
云轩Cloudhin专注Deep learning和高性能计算服务器定制,针对主要深度学习框架(如TensorFlow、Caffe 2、Theano或Torch)进行了优化和设置,在桌面上即可提供强大的深度学习功能。

第9代8核Intel Core i9-9900K不锁频处理器,核心数量与频率更进一步,核芯迭代,动力强升。双路Nvidia RTX GPU,革命性的全新Turing架构,其性能相较上一代显卡提升高达6倍。强强联合,轻松应对如云计算、数据分析、后期制作、技术计算等多任务处理。

更多定制方案请联系客服,云轩布局全国八家直属分公司,将实时响应您的定制需求,做您服务器的贴心管家。