Nature Neurosci: 神经科学的深度学习框架是什么?
深度学习初期可能借鉴了神经科学的经验,比如大脑视觉皮层结构的模拟,层级编码等,但真正促使深度学习大放异彩的,却是源于对神经科学的背离,比如目前没有生物数据支撑的反向传播算法,Relu函数等。虽然这些规则的加入使得深度神经网络在各类任务上的表现得到了极大的提升,接近甚至是优于人脑的表现,但为什么会有这样的效果仍是一个黑箱。
Blake Richards组织一众科学家在Nature Neuroscience上发文,“A deep learning framework for neuroscience”正是回答这个问题。为什么建立神经科学的深度学习框架,神经科学的深度学习框架的内容(是什么),我们应该如何在深度学习框架下发展神经科学(怎么做)。
为什么建立神经科学的深度学习框架
这个问题分为两部分,一部分是为什么要建立,另外一部分是为什么能建立。
为什么要建立?
主要是源于当前神经科学的研究手段的局限,在以往经典的神经科学框架下,我们在研究小范围的神经环路上卓有成效,比如视网膜如何计算运动,前庭-眼反射是如何促进注视稳定的,但是在大尺度的神经环路上,经典的神经科学研究方法有点捉襟见肘。而深度神经网络可能可以用来研究这类问题,其用简化的units来模拟真实神经元的整合和激活特性,而且更重要的是,是通过学习而不是提前设计来实现具体运算的。
为什么能呢?
最近的大量研究表明,深度学习能够帮助我们研究大脑。
首先,深度神经网络在一些情况下很接近灵长类的知觉系统,而且能够调节神经活动;
其次,许多众所周知的行为和神经生物学现象(包括网格细胞、感受野和视错觉)的工作模式和深度神经网络很相似;
第三,计算建模的研究表明,许多学习规则和反向传播算法在为目标函数估计梯度上表现类似,但这些学习规则都不是基于梯度的,因此在估计上有误差(Fig 1)。
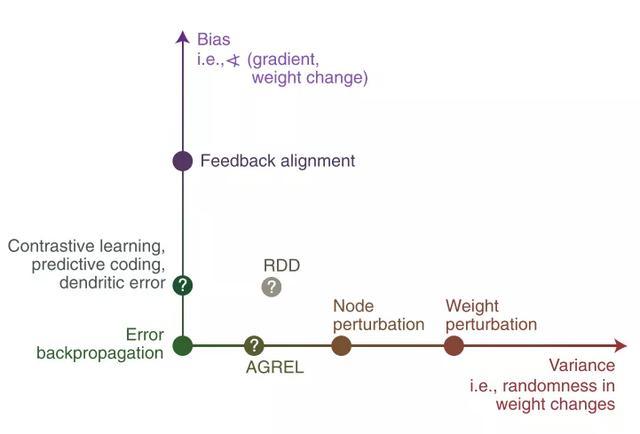
Fig 1. 其他学习规则相对于反向传播算法的梯度估计偏差和方差
因此,基于深度学习的大脑模型不再是像以往那样不切实际,相反确实能够解释神经生物学数据。
神经科学的深度学习框架内容
深度神经网络包括三个基本成分:
目标函数,描述了学习系统的目标,是神经网络中节点权重和数据本身的函数,但他们并非在特定的数据集上定义的。比如交叉熵函数,在机器学习中很常见的目标函数,在各种分类任务中都表现很好,从分类不同品种的狗狗到分辨不同的情绪类别;
学习规则,描述了模型中的参数是如何被更新的。在深度神经网络中,这些规则通常是用来提高目标函数的效率的,在有监督学习,无监督学习以及强化学习系统中都是如此;
网络架构,描述了深度神经网络内的units是如何被安排的。比如卷积神经网络中利用了连接模式,因此相同感受野内输入的内容能够被重复使用。
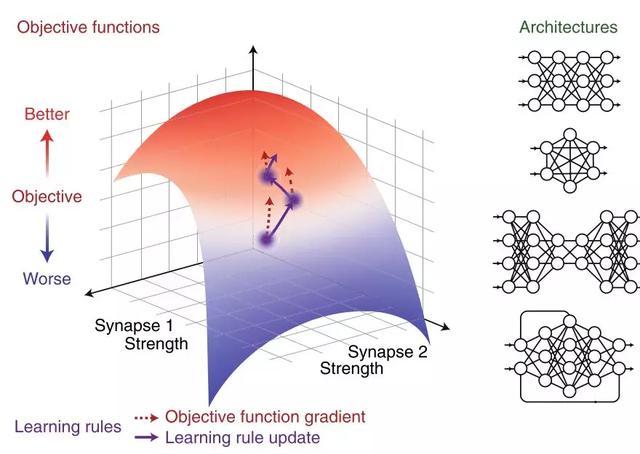 Fig.2 人工神经网络的三个成分
Fig.2 人工神经网络的三个成分在这个框架下,我们不是去关注一个计算是如何实现的,而将这个任务拆分为三个部分去探究:目标函数,学习规则和网络架构。接下来我们将讨论每个部分当前已有哪些工作,这些工作为后续在深度学习框架下研究神经科学提供示范。
如何在深度学习框架下发展神经科学(怎么做)
大脑内网络架构的研究
为了证明由大脑的归纳偏置(inductive biases)所定义的网络架构,我们需要在环路水平上探究神经解剖结构,也必须弄清楚什么样的信息是能够形成环路的,比如动作的信号是从哪里来的等,我们期待弄清楚解剖结构连接的各个方面,从而形成一个整合的生物学marker,来引导网络架构的发展进程。
我们在神经系统的解剖结构上已经做了大量的实验工作,当前正在用一系列的成像技术来量化解剖信息和神经环路信息。目前有几个实验组在探究深度神经网络层次结构的某些部分对应于哪些脑区。例如,纹状皮层可能对应于深度神经网络的早期层,而颞下皮层可能对应于深度神经网络的晚期层。
大脑内学习规则的研究
神经科学中对突触可塑性规则的研究有由来已久。然而,这些研究很少探讨功劳分配(credit assignment)是如何发生的。然而功劳分配问题是深度神经网络学习的关键,也可能存在于大脑中。
不过近期自上而下的反馈和神经调节已成为突触可塑性研究的重点。例如,顶树突如何参与功劳分配,或者自上而下的注意力机制如何与神经递质相结合来解决功能功劳分配问题(Fig 3)。着眼于功劳分配的学习规则的工作使我们能够更好的理解神经可塑性。
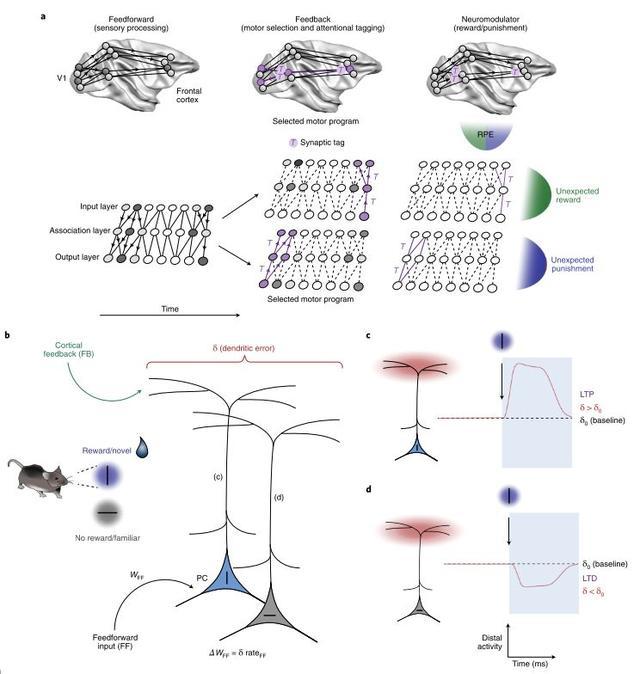 Fig 3. 功劳分配问题的生物学模型。
Fig 3. 功劳分配问题的生物学模型。a.基于注意功劳分配模型是指大脑通过注意和神经递质来处理功劳分配问题。根据这个模型,感觉加工在早期阶段主要是前馈的,然后反馈“标签”神经元和突触以及奖励预测误差(RPE)决定可塑性变化的方向。圆圈表示神经元,灰色度表示它们的激活水平。这些模型预测,负责激活特定输出单元的神经元将被注意反馈标记(T)。然后,如果接收到正的RPE,突触就会增强。相反,如果接收到一个负的RPE,突触就会减弱。这为基于分类的目标函数提供了一个梯度估计。b-d. 功劳分配的树突模型认为梯度信号由锥体细胞的顶树突的错误信号(δ)所。根据这些模型 (b), 前馈权重更新由前馈输入和δ的结合。在一个实验中,两种不同的刺激只有一种被加强,这就形成了特定的预测。(c). 如果一个神经元受到被强化的刺激,那么强化应该会导致其尖端活动的增加。(d). 相反,如果一个神经元受到非增强的刺激,其尖端活动就会相应减弱。
随着当前技术的发展,我们能够在活体上探究突触的变化,也能够直接把突触变化和行为错误联系起来,甚至是直接测量生物模型中学习规则的假设,比如那些需要注意力的,或者是使用树突信号进行功劳分配的(Fig 3)。
大脑内目标函数的研究
在某些情况下,大脑所优化的目标函数可能直接表现在我们记录的神经信号中;而在更多的情况下,目标函数可能隐含于控制突触更新的可塑性规则中。
一些研究试图将实验数据与目标函数联系起来,开始将已知的可塑性规则与潜在的目标函数联系起来,例如,有研究试图通过比较实验观察到的神经活动和在自然场景中训练的神经网络的神经活动来估计目标函数,也有一些方法使用逆向强化学习来识别系统优化了什么。
此外,我们还可以通过寻找给定目标优化的表征和真实神经表征之间的相关性来处理目标函数。另一种新出现的方法是,在控制脑-机接口设备时,观察动物的神经环路可以优化到什么程度。因此,基于以往的文献,探究大脑的目标函数成为可能。
结 语
可能有人会有疑问,如果我们把研究重点从神经元编码特性转移到大脑学习架构、学习规则和目标函数上,看起来我们可能会失去迄今为止所获得的很多知识,比如神经元的方向选择性、frequency tuning和spatial tuning等。但是实际上,我们提出的框架很大程度上是由这些知识所决定的,比如卷积神经网络直接来源于对视觉系统层级特性的研究。
在长期的神经科学过程中,我们倾向于用自下而上的方法来理解大脑,也有人可能会担心为大脑设定目标函数或学习规则可能为时过早,所需要的大脑信息加工细节可能比我们目前拥有的多得多。尽管如此,科学问题必然是在某种思想框架内提出的,而且重要的是,这并不是在呼吁放弃从自下而上的角度来研究大脑,相反是期待深度神经网络框架的提出能够产生新的重要的实验问题。
另外一些研究人员对深层神经网络中的大量参数感到担忧,认为它们违反了奥卡姆剃刀定律(Occam’s razor),可能只是对数据的过度拟合。但是近期人工智能领域的研究表明,大规模超参数化的学习系统可能是反直觉的,但这也是它本身固有的数学属性决定的,这样的学习系统也能够实现良好的泛化,而且实际上大脑本身也包含了大量的潜在参数(例如,突触连接,树突状离子通道密度等),也许,深度神经网络中的大量参数,反而恰恰使他们成为更接近大脑本身的模型呢?
为了在神经科学方面取得进展,需要更多自下而上的信息加工细节和自上而下的理论支撑。在神经元信息加工细节上我们进行了大量的研究且硕果累累,而在建立正确合理的自上而下的理论框架上,一直没有突破性的进展,鉴于现代机器学习能够解决很多人脑解决的问题甚至表现更好,也许从机器学习的角度来指导神经科学自上而下的研究框架可能是一条有效的路径。
如果我们在这种思维模式提供的框架内考虑我们的实验数据,并把注意力集中在这里的三个基本组成部分上:目标函数,学习规则和网络架构,也许我们能够更深入了解大脑。另外反过来,当前我们对深度神经网络的基本原则的探究日益增多,因此我们也能够在大量神经元中测试深度学习的假设。
宽泛科技专注为人工智能、边缘计算、影视后期、动漫设计、商务应用等领域,
提供基于人脸识别、深度学习、视觉计算、VR/AR/MR、桌面虚拟化、
数据存储及数据可视化、视讯会议等信息化解决方案及服务。
如果您有合作需求或宝贵建议,欢迎来信。
邮箱:hezuo@kuanfans.com
合作热线:(021) 5415 5559
官方网站:www.kuanfans.com
